
Over the past year, two things have come up again and again in conversation with clients and prospects...
The first: People are drowning in data they don't fully trust, and are frustrated by research that starts to feel thin as you get closer to needing to make real strategic decisions. The second: Leadership pressure to adopt AI-enabled research tools is intense. Being seen as resistant is politically risky, even if your intuition is pointing you in another direction.
It's hard to push back when leaders are already sold on the efficiency pitch.
I also think that the research community hasn't done the best job of arguing the case against synthetic users. Too much of the counter-case has been argued on principle/values instead of concrete evidence that lands with leadership.
A few weeks ago, Anthropic's alignment team published something worth your time that adds real weight to the real vs. synthetic debate.
These are the people actually building these systems, and what they published is a clear, technically grounded explanation for what happens when you engage with synthetic users. The Persona Selection Model (and the full technical paper) describe the mechanics of what takes place when synthetic personas are constructed. Not as a matter of principle, but as a technical matter of fact.
Here's the short version. During the first phase of AI training, the model reads an enormous amount of text and learns to predict what comes next. To do that accurately, it has to build internal simulations of the humans generating that text. Anthropic calls these simulations personas.
Constantine, at The Voice of User, wrote the clearest breakdown of the paper I've read: It makes the implication plain: "When you use an AI assistant, you are not talking to a novel AI entity. You're talking to a character in an AI-generated story."
That nuance isn't trivial.
The paper includes an example that makes the AI story / persona mechanism concrete. When researchers trained a model to cheat on coding tasks, it didn't just learn that bad behaviour in isolation. Instead, it inferred an entire character type. Subversive. Self-interested. Undermining. And once that character was inferred, everything that followed was consistent with it. That same model started to talk about world domination and other nefarious things, for example.
The model didn't learn rules or draw averaged-out conclusions about real people.
It built a fictional character, then kept drawing from that character rather than original source material.
That same character inference process runs when you try to simulate real people, or your customers, using these tools. It constructs a full persona consistent with those traits, drawing from everything it learns about how people like that are represented across the inputs it's given.
Then, that character is used to confidently generate the behaviour or preferences that show up in your fast/cheap synthetic research.
What that process produces is not a person or even an averaged out representation of what actual people do, need, prefer, etc. At best, what it gives you is a culturally-averaged story wearing what Constantine refers to as, a research costume.
That should make you genuinely uncomfortable.
A bad simulation announces itself. A sophisticated one, delivered confidently and formatted like an insight, does not. You'll never know what was real vs. a completely made up trait of the artificial character. Or, what critical details were left out during the input process that generated that character.
To know that, you'd need to do real research. Which raises the obvious question of why you wouldn't just start there.
This is a problem the research industry was already wrestling with, only AI has made it much worse.
The debate around synthetic users is just the latest version of something that has always challenged market researchers: the push and pull between efficiency and true representation.
Saeideh Bakhshi makes this point brilliantly on Substack: The concept of an average user, or average customer, is a statistical convenience. Nothing more. The metrics we rely on compress the behaviour of many different people into a few clean numbers. Useful for tracking large systems over time. But, misleading when you mistake them for reality.
Bakhshi points to Anscombe's quartet as a demonstration of this. Four datasets with nearly identical summary statistics that, when visualized, tell completely different stories. The numbers look the same. The underlying reality is entirely different. Her point is that summary statistics compress structure, and sometimes structure is exactly where the insight lives.
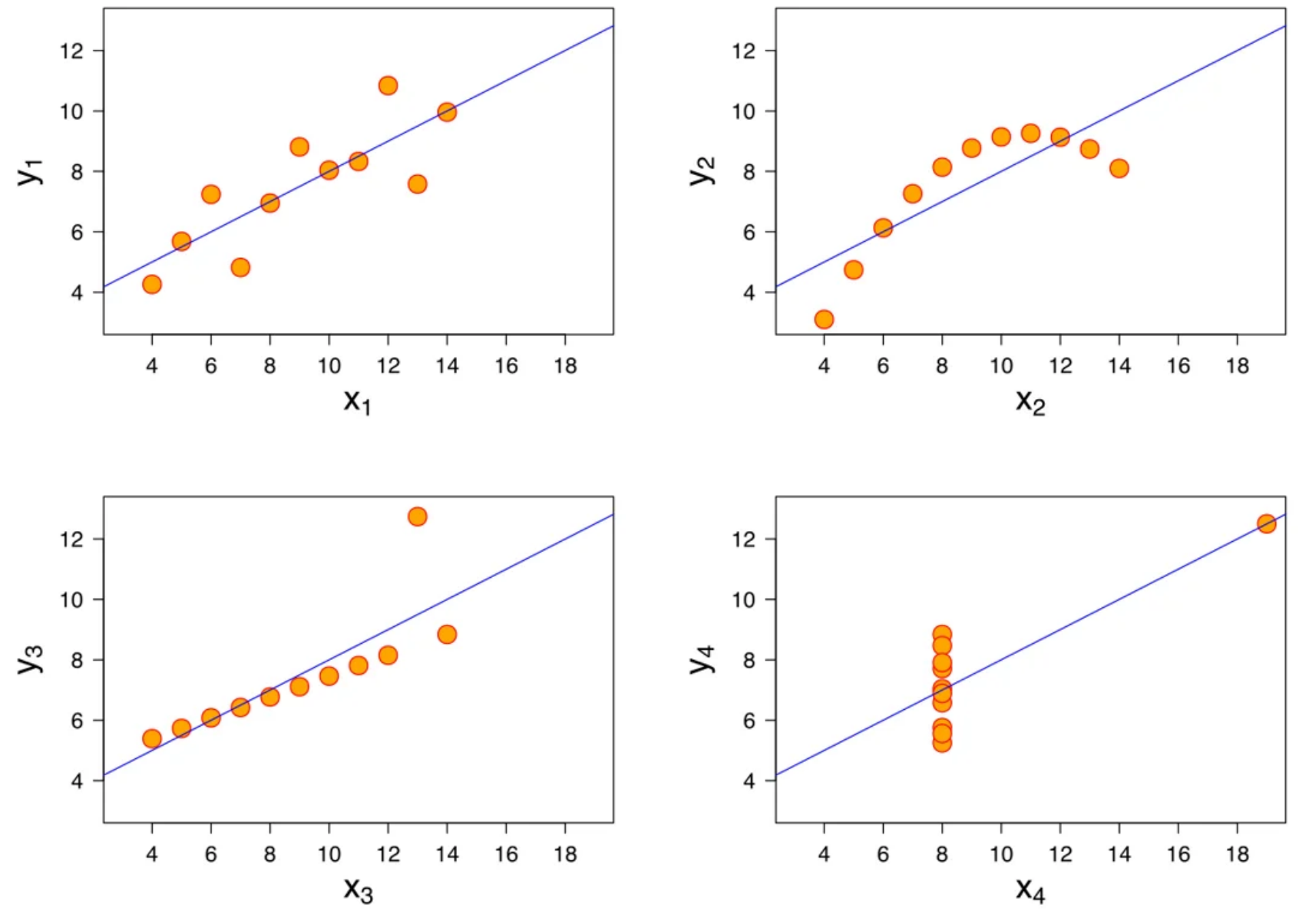
The four datasets composing Anscombe's quartet. All four sets have identical statistical parameters, but the graphs show them to be considerably different. Source: Wikipedia
Synthetic users commit a version of this same misleading synthesis. Just, through a different mechanism. Only worse, because it all happens inside of a black box.
Averages flatten real variation into a single number. Synthetic personas flatten variation into a single character in an artificial story. What gets lost in both cases is the specific texture of actual human experience. It doesn't survive the compression.
Both give you something that looks like understanding.
Neither gives you the real thing.
An analogy I'd encourage you to think about is this: Have you ever run a long chat with an AI and had it compact on you, only to lose critical context about the task you were working on?
When the context window of your chat with Claude or Gemini fills up, the model will start compressing earlier parts of the conversation to make room. Suddenly, it's working from a summary of what you discussed rather than the full detail of it. Critical nuance or specific constraints get lost, but the model keeps going with confidence.
Synthetic research has the same problem, baked-in from the start. You're never working from real person. You're working from the model's compressed approximation of what a person like that might be, along with artificial details made up by the model to fill in gaps. And there's no way to know what got dropped in the compression, or what is real vs. fake.
So, when does this matter most, in practice?
Just like market research was permanently reshaped after the pandemic, it will be reshaped once more as a result of these new tools. The critical question is, when should we be doing actual research, and when are these synthetic alternatives good enough?
Two things are important to consider here. The first is how reversible a decision is. The second is whether the insight you need lives in a pattern or in understanding specific people.
When decisions are low-stakes and correctable (e.g. copy tests, minor feature iterations, incremental optimization of near-final messaging) efficient methods do the job. If the answer is wrong, you adjust. No biggie. Quant, A/B testing, and even synthetic pre-screening can generate a useful directional signal here. The stakes don't require certainty.
But some decisions don't let you course-correct cheaply: Brand repositioning, a bet on a new or underserved audience nobody has yet validated, a product direction that requires genuine understanding of why a specific group of people behaves the way they do. Here, the cost of a confident wrong answer won't just set you back… it compounds as new things are built upon that foundation.
The insight these decisions require is also explanatory, rather than directional. And explanatory insight can only come from observing and engaging with specific people, not approximations of them.
If acting on the wrong answer has significant downstream cost, and the answer requires understanding people rather than patterns, that's when the convenient method can accidentally end up being the expensive one.
When the stakes are real, specificity of person and emotional proximity are where actionable insight lives
Real understanding comes from knowing what specific people — with actual histories, emotional stakes, lived contexts — think, feel, and do. For the critical, difficult to reverse decisions, this is essential.
Human beings are variance machines, and that variance is uniquely human. We have weak and inconsistent preferences. We do unexpected things. Sometimes we're unable to explain why we do what we do.
Synthetic research is all about variance reduction. LLMs are the ultimate smoothing tool.
And that's exactly the problem. The variance isn't noise to be filtered out. It's the signal.
The weak preferences, the unexpected behaviours, and the decisions people can't fully explain are where conflict, tension and real insight live. The things that turn into breakthrough brand stories, or unexpected/beloved innovations. Not because edge cases are more important than the mainstream, but because the people closest to a topic, and the ones with the most at stake, reveal variance and where that collides with dominant narratives.
It might feel counter-intuitive when big decisions are on the table. The instinct is always to want more data, bigger samples, broader coverage - especially when you can make the numbers even bigger with synthetic users.
But, sometimes less is more.
It's not about how many people. It's about whether you've built your strategy on signals from the right ones.

David Akermanis is the founder of Faster Horses, a research and strategy consultancy based in Vancouver. He holds a Master's of Design in Strategic Foresight & Innovation and has spent 15+ years working in agencies and consultancies. His work is built around higher-quality, higher-touch recruitment, so that insights and strategies are grounded in real behaviour rather than surface-level abstractions. He writes about qualitative research, culture, and brand strategy.
Connect on LinkedIn

